Finally, AI translations your business can trust
Unbabel is the first Language Operations Platform fueled by an always-on AI that empowers you to bring in human review when needed – so you can save as you go and easily uplevel quality to meet your business needs.
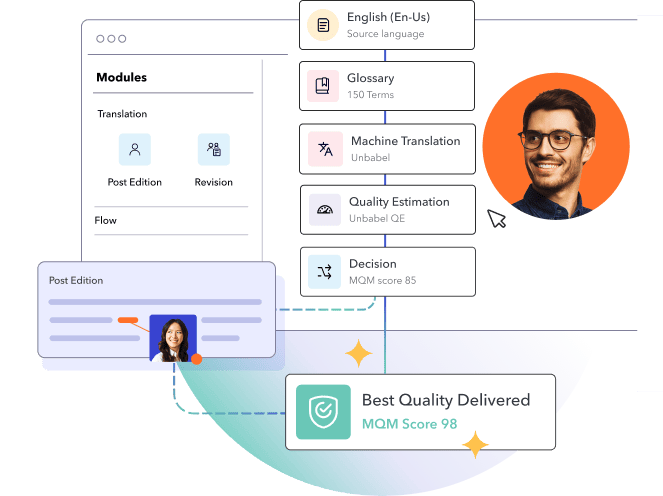

What is Unbabel?
Unbabel is the next-generation LangOps Platform, and all-in-one solution for your global translations. With real-time quality reporting, customization, transparency, and control — we empower you to meet your business goals for cost, speed, and quality.
Worldwide leading brands trust Unbabel



Reduce costs with AI driven, dynamic workflows
Unbabel automates where possible and brings in humans where needed – directly passing the savings back to you.

Customize workflows for your business goals
Configure translations for speed, quality, and cost that align with your needs by market or content type.

Have confidence in every single translation
With our unique AI quality estimation, you get full visibility into performance to see how your translations rank and where you can optimize.
Want to see how your translations are performing?
Verify the quality of your translations or explore the best model from other third-party providers with our award-winning Quality Estimation technology.

We work where you work
Unbabel seamlessly integrates with your favorite apps and platforms to translate your existing workflows for a global stage. That means no disruptive onboarding or flipping between applications to engage international audiences. We work with you so you can keep working the way you want.






See why customers love Unbabel
Unbabel is easy to set up; their procurement and implementation teams made the onboarding easy and the integration to Zendesk was seamless and very fast.
Fabien Dupont

Wargaming
Thanks to Unbabel, we can have highly skilled agents in all the markets we operate, optimizing resources and avoiding problems of lack of coverage with one language or another.
Filippo dell'Anno

Rakuten TV



A proudly consistent leader in the translation industry





