
We are happy to share some exciting work we have been developing this year at Unbabel, alongside external research collaborators: QUARTZ (QUality-AwaRe Machine Translation), an initiative funded by the ELISE Open Call and focused on building responsible machine translation (MT) for conversational data.
Over the years, in particular more recently, MT systems have shown impressive improvements in translation quality. However, some translations produced by these systems still present severe mistakes. These mistakes can have drastic consequences, especially in types of content where such severe errors cannot be tolerated, such as health, legal, and finance-related texts. For example, in the text below, “intoxication” should have been translated as “food poisoning”:
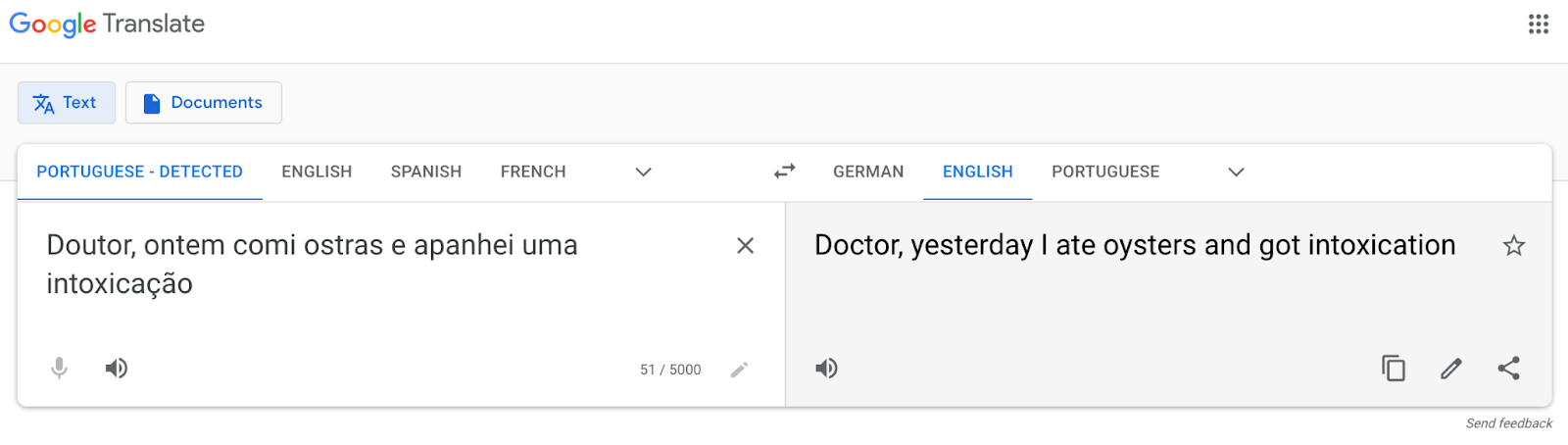
Preventing these errors when using MT systems is extremely important to fulfill Unbabel’s commitment to responsible Machine Translation. The QUARTZ project aims to enable MT systems to be more responsible while generating translations, and, in particular, to be more resistant to generating severe errors. This is achieved by equipping MT systems with awareness of the quality of the translations they produce, so that they generate safer and more adequate translations. With QUARTZ, Unbabel will enable the usage of MT-only solutions for content types and markets in which severe errors are not tolerated and for which quality-aware MT is game-changing.
During the project, we developed an approach to machine translation that uses COMET (an automatic machine translation evaluation metric developed by Unbabel) and OpenKiwi (an automatic machine translation quality estimation – QE – tool developed by Unbabel) to inform the MT system of its own translation quality while generating translations. We did so by generating (sampling) a series of different and diverse translations with the MT model and then using a separate model to score and rank the translations according to their translation quality, as measured by COMET or OpenKiwi.
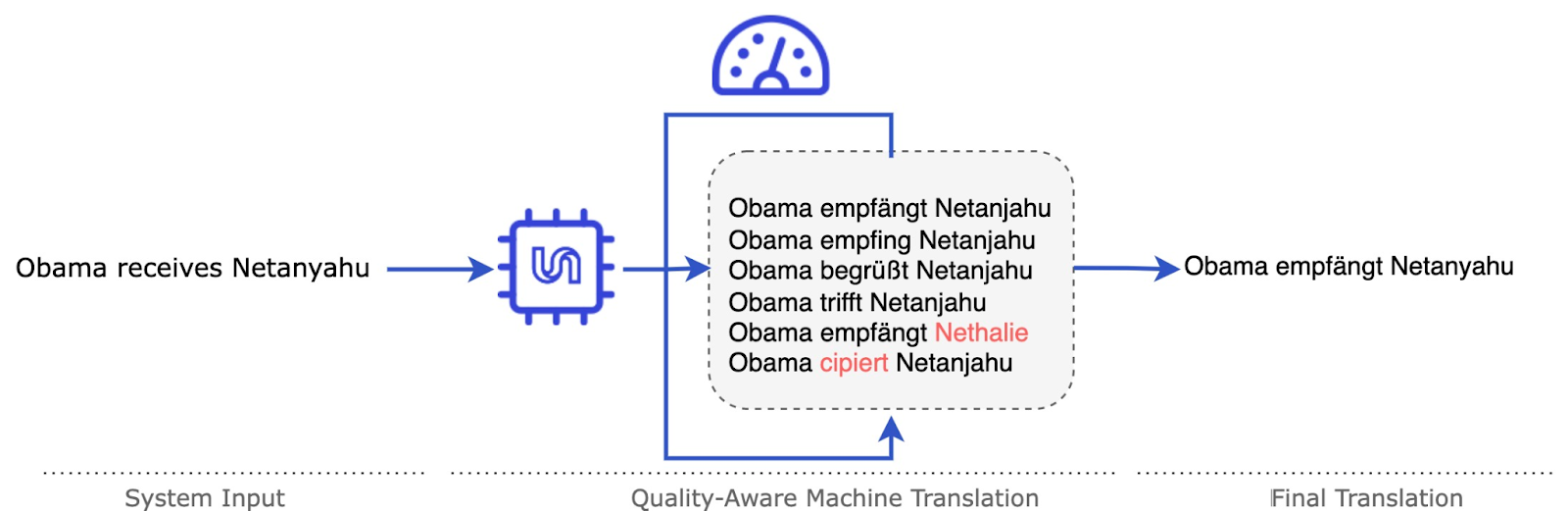
The image above shows the process previously described, in which an MT system that translates between English and German receives a sentence in English, a series of translations are generated with the MT model, and then a re-ranker scores and chooses the best translation according to COMET or Quality Estimation out of the sampled translations.
The re-ranking is implemented in four different ways:
A fixed re-ranker, which orders the translations according to their quality estimation score.
A trained re-ranker (a re-ranker that is tuned on a held-out data set, in which different features are used to represent the source and its hypothesis translation, among them Kiwi).
Minimum Bayes Risk (MBR, an approach that compares every translation in the sampled translation list against every other translation).
A two-stage re-ranker that combines the trained re-ranker and MBR.
Our experimental results indicate that there is a reduction, on average, of up to 40% in severe errors (critical plus major) across different language pairs. All these approaches and first results are described in detail in our paper recently presented at the NAACL 2022 conference.
While developing the quality-aware MT approach, we noticed that two factors were decisive in improving automatic evaluation metrics: Making automatic evaluation metrics run faster and improving their precision in detecting severe errors in translations. Running automatic evaluation metrics faster is really important because with the sentence-level re-ranking approach we need to run these metrics for several translations of the same source sentence, which is time-consuming.
This need led to the development of COMETinho, a faster COMET that can reach a speed-up in inference time of 37% with the loss of only 1 correlation point across three different language pairs. This work led to a peer-reviewed publication at EAMT 2022 that was chosen as the best paper award of the conference.

With the promising results during the course of this project, we are now working on expanding the assessment of the approaches described here on different content types and language directions. We are very excited to see the impact the work developed can have on both opening new market possibilities, through the enablement of MT for new content types, and improving the translation quality of current content types.





