
 Two months can be very long or very short. My time as a Development Intern at Unbabel felt like both. It was an incredibly rewarding experience, affording me the opportunity to acquire many new skills.
Two months can be very long or very short. My time as a Development Intern at Unbabel felt like both. It was an incredibly rewarding experience, affording me the opportunity to acquire many new skills.
As part of Unbabel’s Portal Team, I was tasked with building a chatbot for one of the company’s internal Slack channels.
Here are the highlights.
Task assignment: Bring on the challenge
Portal is a self-service Language Operations hub that helps Unbabel’s customers operationalize the use of language across their business. It provides subscription and usage data, as well as insights on key translation metrics, such as volume and quality.
Portal offers a help-related Slack channel where internal users can inquire about different topics.
The idea was to create a self-serve chatbot that could understand what the users were asking and retrieve the most appropriate answer from the FAQs (and the FAQs only).
Tasks included:
- Creating the backend for the bot
- Handling all integrations with the Slack API
- Creating everything NLP and ML-related
- Creating the frontend for managing some of the model’s configurations
This was a true full-stack project: Backend, Data Science / Artificial Intelligence / NLP, and Frontend.
So, buckle up as we dive into the process.
The masterplan
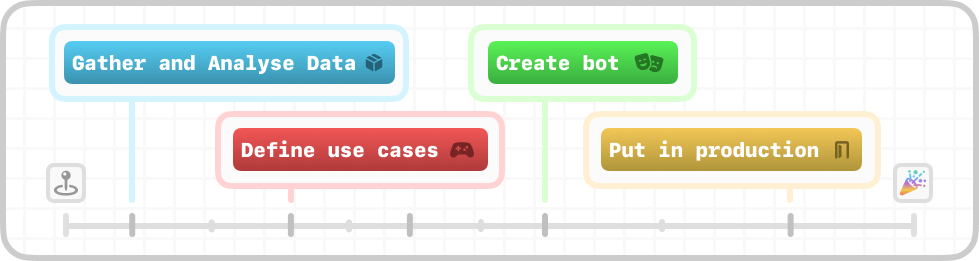
First, I created a sketch of how to build the bot (easier said than done):
Mining our data
The data we had on our FAQs was invaluable: We needed to unpick what it could yield and its limitations.
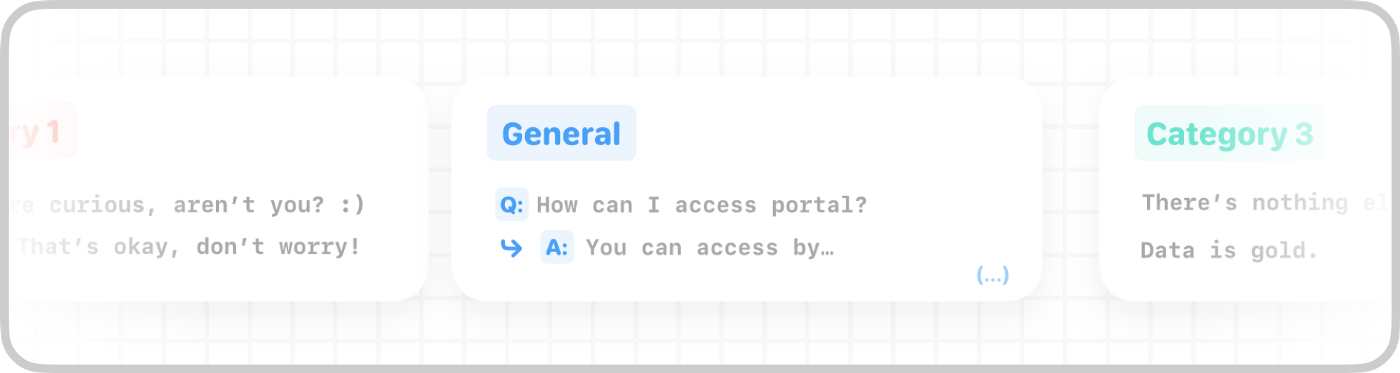
Example of one Question-Answer pair for one of the categories (General)
As shown in the image above, our FAQs, like most FAQs, offer direct, concise answers. We had 50 entries. The data was scarce.
Fortunately, we found another set of data: 150 questions that were asked in the Slack channel during the last year. I manually retrieved and categorized each of these questions.
As the questions were asked by humans, they were very different from the FAQs: They were more detailed and less direct — and instead of being, on average, quite short, the prompts were more complex.
Conclusions, conclusions, conclusions — Unpacking the data
With this data in our hands, we applied regular NLP pre-processing and a data science pipeline. What we found was an interesting pattern: After removing the stop-words, there was a distinct group of words for each category, almost like a fingerprint.

Example of some relevant keywords for one category (General)
For the General category, the words design, Portail, access, customer, and user appeared with more frequency than any others.
Defining the use case
Before we dive into the technical part, it’s worth noting that the bot would analyze every message sent in the Slack channel. Only when the prompt matched our rules, however, would it try to retrieve the best answer and share it with the user.
The fun begins: Creating the bot
The idea to create the bot was quite simple. First, we needed it to identify whether the question being asked was 1) Indeed a question, and 2) Relevant in our context. In this case, the context was anything to do with Unbabel’s Portal. However, we can generalize the context to be tech-related.
1. Question classification

In the image above, Example 1 is a text input that is both a question and relevant. Example 2 shows text that is relevant, but not a question, and Example 3 is an input that is a question, but irrelevant.
To create a question classifier that outputs ‘yes’ if the input is a relevant question, or ‘no’ if it’s not, we had to collect more data.
To do this, we harnessed the TechQA dataset: This dataset has the same structure as our FAQs, minus the category. It allowed us to test whether the bot could detect if a given input was a question and if it was relevant to a tech-related context. The TechQA was a perfect match.
After testing multiple approaches, either by experimenting with different pre-processing methods or by using different AI models, we discovered the pipeline that worked best, reaching impressive results:
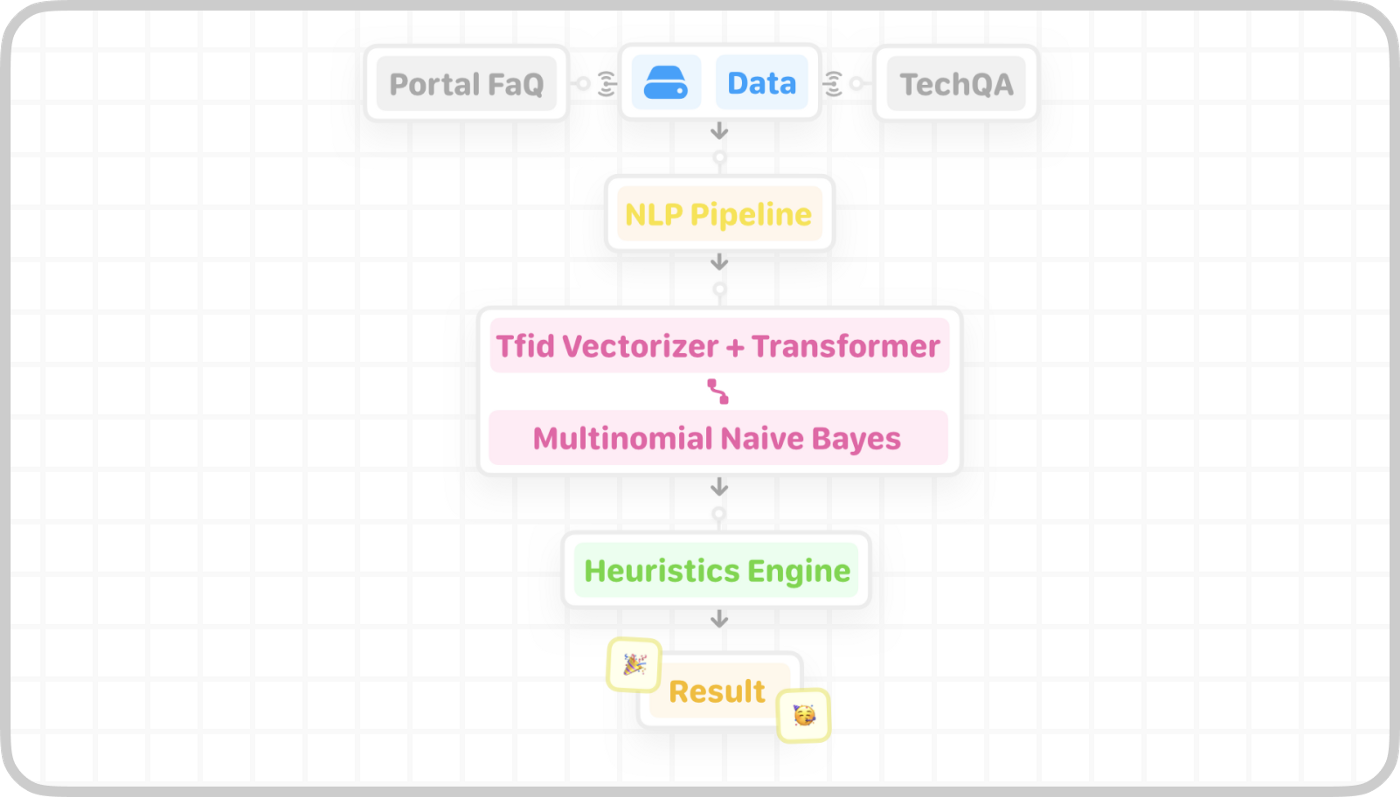
Pipeline for the Question classification system
Learning by heuristics
Think back to the keywords we obtained when analyzing our data — design, portal, access, customer, and user. We found that for every category, some keywords stood out.
For each word in the input sentence, if there was a match with any of the keywords, we added more weight to the probability that the result was ‘yes’ (the prompt is a question and it’s relevant). This helped with the ‘relevant’ detector part of the model.
Regarding the ‘question’ detector part of the model, we helped the model by using some NLP common question-detection patterns, such as checking whether the sentence ended in a question mark, or started with “How can…”
For our domain, these two helper methods improved our results.
2. Question categorization
Now that we could classify whether we should answer an input or not, the next step was to give the correct answer to the user. To do so, we narrowed our search field: Instead of retrieving the best answer from the entire FAQs, we first identified the category to which the question belonged.
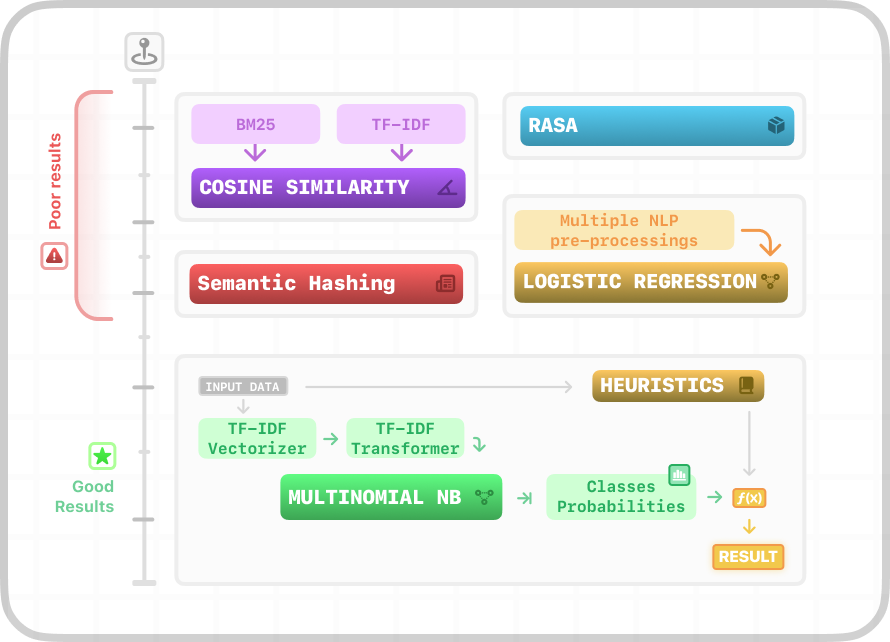
In the red section (Poor results), the methods bore insufficient results. The green section (Good results) is the chosen pipeline
Regarding the training and testing data, the questions manually received from the Slack channel and the FAQs are categorized; thus, they composed our data for the categorizer.
The image above shows some of our experiments, like RASA and Semantic Hashing. They all gave poor results. It was only when we moved to Multinomial Naive Bayes with a Heuristics Engine that the results improved.
Essentially, the classifier returned a probability vector of a question belonging to each one of the categories in the FAQs. Then, with the Heuristics Engine for each word in the question, if the word belonged to any of the category keywords, we added a small value to that category. The values to be added were manually set. Thus, we had a table of Keyword-Category-Weight entries. Without the heuristics, the accuracy was around 50%. With them, it rose to almost 90%.
3. Question-answer pairing
Now came the fun part: We were ready to retrieve the most appropriate answer for the user’s inputs.
We used the Haystack Python library. With Haystack, and using the cosine similarity as the measure of similarity between sentences, we employed a pre-trained sentence transformer, available on Hugging Face, called all-MiniLM-L6-v2. This model maps sentences to a 384-dimensional vector, from which we can calculate the similarity for each of the FAQ entries, and retrieve the most similar.
When looking for the best answer, we searched both the predicted category and the entirety of the FAQs (as the predicted category might be wrong). Then we returned an average of the results.
Future optimization
As I stated earlier, data is gold, and, in this case, it was our biggest limitation. If a user asked for something not present in the FAQs, the result wouldn’t make sense. That was an intrinsic limitation for which we couldn’t do a thing.
To overcome — or at least ease — this limitation, we introduced a thumbs-up and thumbs-down voting system. After some months of use, we would be able to see which answers obtained poor results and either tweak what we could (the keywords and respective weights) and/or add new FAQ entries.
The deployment phase was entrusted to Mathieu Giquel, Backend Developer in the Portal Team, while I prepared the Docker Containers.
Developing the frontend
On top of backend development, diving into data science, Artificial Intelligence, and NLP, I also have a keen interest in design and frontend development. I created a frontend with two main objectives: Visualizing the FAQs and editing keywords. The frontend was entirely built with Vue 3 and Tailwind CSS, and it connected directly with the AI model’s backend (that, in turn, handled the connections with the database, stored in an AWS S3 bucket).
It was completed with animations and transitions for the sticky headers.
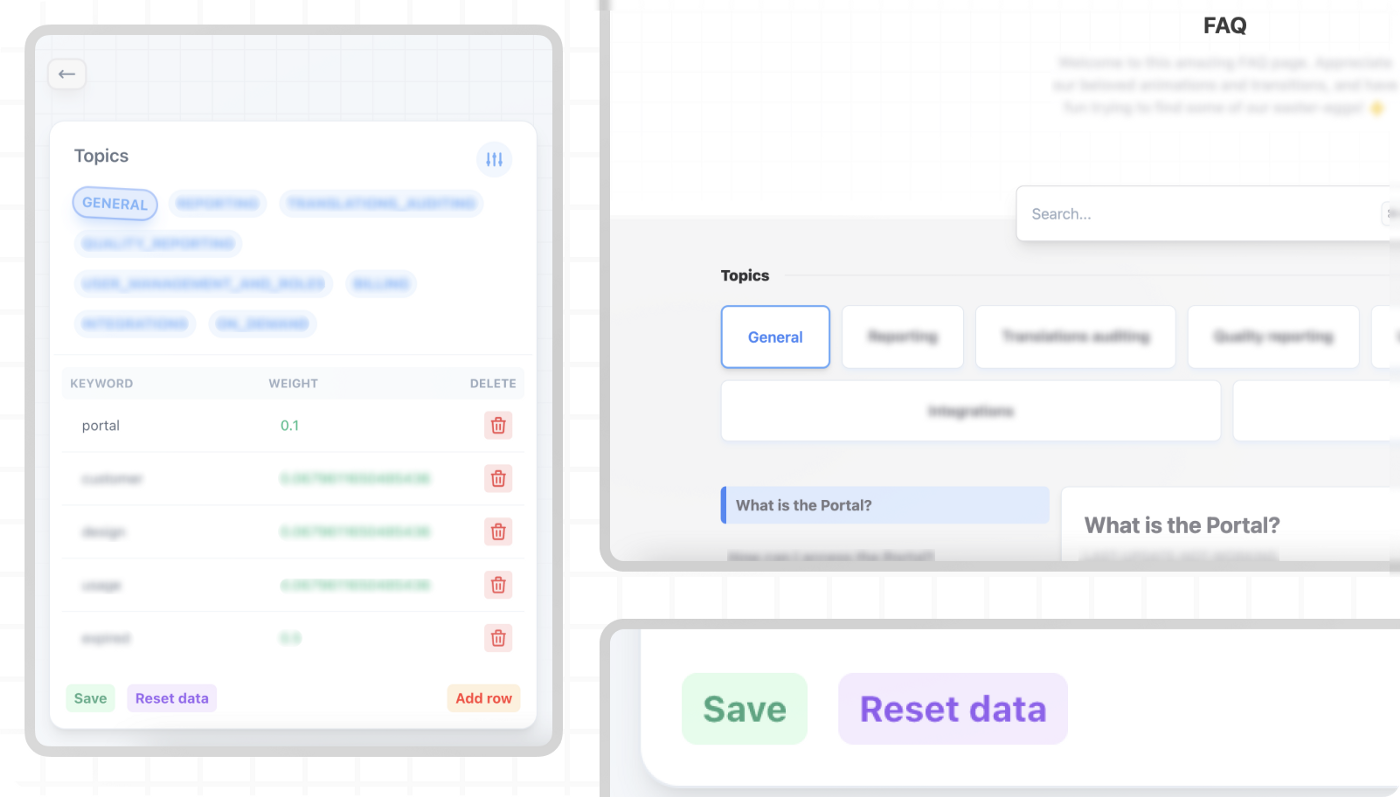
Close-up shots of some parts of the frontend UI
Mission accomplished
A small part of me will always be in Unbabel’s Slack channel. This experience taught me so much: I created an end-to-end system with two backends (for Slack and the AI models), learned more about data science and AI in the real world, implemented a mini-frontend in Vue 3, integrated it all by creating Docker Containers and using Docker Compose, and started working on an internal frontend project. All while following the team’s best practices and rules, which allowed me to learn a great deal about frontend development.
It was a great journey and a fantastic opportunity to work in a company with a demanding environment, in a supportive team (in particular Lawrence de Almeida, Maria Bernardo, Mathieu Giquel, Nuno Infante, and Luís Bernardo), while learning more about many areas of interest.
In case anyone is wondering, I highly recommend applying for a Summer Internship at Unbabel. Regardless of your interest area — frontend, ML, or any other — you are going to love it!





