We are releasing an API for accessing AI models developed by Unbabel to evaluate translation quality. These models are widely established as the state of the art and are behind Unbabel’s winning submissions to the WMT Shared Tasks in 2022 and 2023, outperforming systems from Microsoft, Google and Alibaba.
You can now request access in order to integrate this API into your translation product.
Read on to learn about:
- What is Quality Estimation (QE) and how it can impact language operations
- How QE models get trained and the role of quality datasets
- Specific examples of how your business can benefit from the QI API
- What kind of quality report data you can get using Unbabel’s QI API, supporting high level decisions as well as granular improvements
- How to access and utilize the API today
Automatic translation quality evaluation, known as Quality Estimation (QE), is an AI system that is trained to identify errors in translation and to measure the quality of any given translation without human involvement. The insight that QE provides, instantaneously and at scale, allows any business to get transparency into the quality of all their multilingual content on an ongoing basis.
Supported with both high level quality scores and granular translation-by-translation reporting, businesses can make broad adjustments, as well as surgical improvements, to their translation approach.
The Unbabel models accessed through the API are built with our industry-standard COMET technology, which are consistently recognized as the most accurate and fine-grained in their class. These Unbabel models we provide access to via the API are of even greater accuracy than their state-of-the-art open source counterparts.
How do we deliver greater accuracy? This is all down to the Unbabel proprietary data used to train the model, a result of years of collection and curation by Unbabel’s professional annotators. These datasets total millions of translations covering a wide range of languages, domains, and content types, and crucially, the data catalogs the myriad ways in which translations can fail and can succeed.

How can your business benefit ?
- You are utilizing a multi-vendor strategy for your translations and would like to get visibility into the quality of the various translation providers
- Your organization has an internal community of translators that you would like to audit for quality
- You have developed your own machine translation systems and would like to implement your own dynamic human-in-the-loop workflow, either in real time or asynchronously
What data does the API provide?
The Quality Intelligence API provides the user with direct access to Unbabel’s QE models, which provide predictions on two levels:
- translation evaluation, and;
- error explanation of a specific translation evaluation
Translation evaluation returns a translation error analysis following the MQM framework (Multidimensional Quality Metric). The prediction lists the detected errors categorized by severity (minor, major and critical), and summarizes the overall translation quality as a number between 0 (worst) and 100 (best), both at for sentence and at for the whole document.
Error explanation adds a detailed error-by-error analysis. It labels the type of error, identifies the part of the source text that is mistranslated, suggests a correction that fixes the mistranslation, and provides explanation of this at the level of the error, the sentence, and the document.
Together, these predictions provide the user with holistic insight into translation quality, from the highest level of aggregated MQM scores to the granularity of individual error analysis and explanation. It is this dual reporting that lets users make high level decisions as well as granular enhancements to make important improvements.
Why does automatic quality evaluation matter?
At Unbabel we have continually and consistently invested in QE. We believe QE enables responsible use of AI-centric translation at scale, which is the present and future of the language industry.
Machine Translation (MT) is a powerful tool, especially when augmented by context-rich data and complementary algorithms performing language-related tasks in the translation process. However, without visibility into MT quality, businesses will never know if their translations deliver value, and whether or where to spend the money and time to make improvements. Until a catastrophic mistranslation reaches the customer, of course. With QE, there’s no need to compromise on quality, since businesses can determine which automatic translation needs human correction, and which is good as is. We believe that this is responsible use of Machine Translation.
Professional human translation can also benefit from QE. With errors flagged upfront, translators can focus on outstanding errors, letting them direct time and attention to critical segments instead of large swaths of already correct translations. This is a big efficiency increase that human translators can capture today.
API Reporting Examples
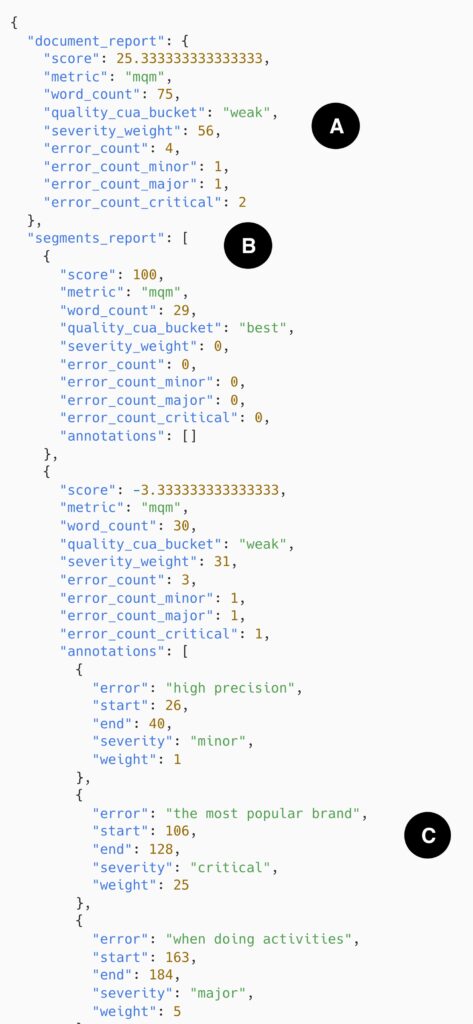
A – The user provides a translated document consisting of three translated segments
B – The user specifies that the translation is expected to be from Chinese (Simplified) to English (British) and in an informal register(These example translations are taken from the test set of the WMT23 QE shared task.)

Evaluation
A – The overall translation quality of this document is predicted to be very low. With 4 errors, 2 of which are critical, the translation obtains an MQM score of 25 out of 100, earning it the label “weak”
B – Breaking down the evaluation per segment shows us that the errors are concentrated in the last two sentences, with the first sentence deemed to be of perfect quality
C – The error span annotations list the errors that determined the evaluation score. The error spans locate the error text, their severity, and the penalty (weight) that severity incurs. The MQM score is computed from the sum of these severity weights (1 + 25 + 5 = 31) and is normalized by the number of words (30) following the formula (1 – 31 / 30) * 100 = -3.33. This formula also applies at the level of the document, using the document total severity weight and word count.
Explanation endpoint
A – The explanation prediction explains – at each level of the analysis
B – The prediction also provides suggested corrections at each level of the analysis
C – Each error is categorized following an error typology and the part of source text involved in the mistranslation is provided for each identified error

Access the API
- Get immediate access to the API
- Or see the API tutorial or the API reference for for full documentation
- Want to see Unbabel QE in action right now? Try the interactive Quality Intelligence demo to evaluate your own translations. Or try the MT demo to see how our QE model can help you identify the best Machine Translation for your content.