Machine translation (MT) has come a long way. From the early rule-based systems to the advent of neural networks, the field has seen remarkable advancements. For more than a decade, Unbabel has been at the forefront of this evolution, leveraging state-of-the-art technologies like quality estimation (QE) to enhance translation accuracy and fluency.
However, despite all the progress, traditional MT models still face significant challenges. They often struggle to understand context, handle complex language structures, or adapt to different domains. While domain adaptation is a partial solution, training personalized models for terminology, style guides and tone of voice is costly and always lags behind current translation dynamics. What’s more, in many cases, the machine translation still requires some type of review and correction by a human.
This is where the emergence of Generative AI and Large Language Models are poised for a major step change. Due to their vast knowledge and capacity to understand and generate human-like text, they are revolutionizing the field of natural language processing, with the capacity to comprehend context, handle nuances, and even engage in multilingual conversations with remarkable coherence. Now, we at Unbabel want to turn the power of this technology onto translation.
In this blog post you’ll learn about:
- The key role of data in fine-tuning and training a large language model
- How RAG (Retrieval Augmented Generation) powers ongoing adaptation and personalization
- Unbabel’s benchmark data privacy policy for LLM development
- The results that backup why LLMs are going to lead AI translation
- How the combination of TowerLLM and Quality Estimation drive significant improvements in translation efficiency, visibility and performance
This is an output of the European Project UTTER (Unified Transcription and Translation for Extended Reality) Funded by the European Union’s Horizon Europe Research and Innovation program under grant agreement number 101070631. For more information please visit: https://he-utter.eu/
The details are in the data
With the release of TowerLLM, our groundbreaking multilingual LLM designed specifically for translation and related tasks, Unbabel is at the forefront of this massive shift, building on years of AI research and development, and paving the way for a new era in AI translation.
The proprietary version of TowerLLM lets Unbabel customers benefit from superior translation quality and performance across the entire translation workflow (an open-source version of TowerLLM is available), since it was built on both the publicly available data as well as Unbabel’s proprietary, best-quality translation data.
Let’s run through how we designed and built this iteration of TowerLLM. TowerLLM is different because it is multilingual by design. We trained it on an extensive dataset of high-quality multilingual data, meticulously curated and filtered using our proprietary quality evaluation LLM, COMETKiwi. While well-known large language models like GPT-4o are trained on data from various languages, that data is by definition of mixed and uncertain quality, contaminating the training and therefore the performance on the model. TowerLLM benefits from training, testing, and optimizing on this best-quality data, meaning it excels at comprehending and producing text in different languages.
We take this a step further with fine-tuning the model to perform specific translation tasks, one being translation, but also source correction, named entity recognition, machine post-editing and others that streamline the translation process, reduce errors and increase consistency. To perform these specific tasks, we created a separate, specialized dataset called TowerBlocks comprised of prompts and examples in each language pair from public and internal data. This extensive data curation for fine-tuning takes TowerLLM beyond the simple translation step and supports the entire translation process.
Now that we’ve talked about training, let’s talk about ongoing enhancement. Sometimes called On-the-fly-adaptation, Few-Shot training or RAG (Retrieval Augmented Generation), TowerLLM will be capable of adapting and personalizing to customer specific needs in real-time, making it a powerful tool for the changing requirements and market conditions faced by businesses. On-the-fly-adaptation uses previous high quality translations as a reference point to adapt on an ongoing basis to specific domains, styles, new terminology, and so on, using just a few examples, and a matter of minutes after the translation happened. This incredibly rapid training, leveraging only high quality inputs, lets Unbabel customers adapt to changing conditions consistently, and since it’s automated, at a low cost.
In the current release, TowerLLM performs:
- Machine translation across 18 language pairs, ensuring accurate and fluent translations for a wide range of languages.
- Named entity recognition to localize names, metrics, and codes (e.g., currencies, weights, locations, brands), enabling culturally relevant translations.
- Source correction to eliminate grammatical and spelling errors, enhancing the quality and readability of the translated content.
- Machine post-editing that automatically improves translations based on AI-powered quality estimation, reducing the need for manual intervention.
Over the coming months we will enrich TowerLLM with more language pairs and more translation tasks to further enhance and improve the translation process.
Data privacy, uncompromised
Achieving this level of performance requires a combination of public and proprietary data, and as such, training and deploying TowerLLM was consistently underpinned by our robust Privacy and Security Measures. It’s no secret that training AI models requires significant amounts of data, however, that doesn’t mean that it shouldn’t be secure. We’ve seen many AI businesses provide unclear or incoherent explanations for how they treat and use sensitive data. Not at Unbabel. We’re committed to ensuring our customers’ data is safe and secure at all times.
Through a tried and tested process, we deliberately anonymize sensitive information through meticulous protocols before model training, meaning that no private data ever makes it into the model. In addition, we can follow customer needs for scrubbing data through our proprietary Eraser technology, allowing us flexibility to meet customer needs when TowerLLM is deployed in production.
Why LLMs for translation are here to stay
In the release of TowerLLM, Unbabel is already beating out competitive models, both in the same Generative AI space like GPT-4o as well as more traditional MT players like Google and DeepL. Based on how we built on huge public models, trained on filtered best quality data, and provided instruction on rich prompts, TowerLLM is geared to solving these problems for customers in a way these competitors are not.
This makes a lot of sense. In this era of widely available large language models, the opportunity is in customizing the model, not building it from scratch. That way, companies like Unbabel are able to provide focused, value-add AI products that benefit from the deep contextual understanding and sophistication of LLMs and turn it on specific, concrete problems. In a recent blog post commenting on the release of GPT-4o, Sam Altman said: “Our initial conception when we started OpenAI was that we’d create AI and use it to create all sorts of benefits for the world. Instead, it now looks like we’ll create AI and then other people will use it to create all sorts of amazing things that we all benefit from. “ With TowerLLM, this is what Unbabel is doing in translation.
Not everyone is in agreement, with some stating that specific neural MT still holds primacy as the leading AI translation, however, our results say otherwise.
What do the numbers say? We ran a series of experiments using proprietary customer data across translation in 14 language pairs, four domains in one language (English-German) and on multilingual reasoning and comprehension tasks.
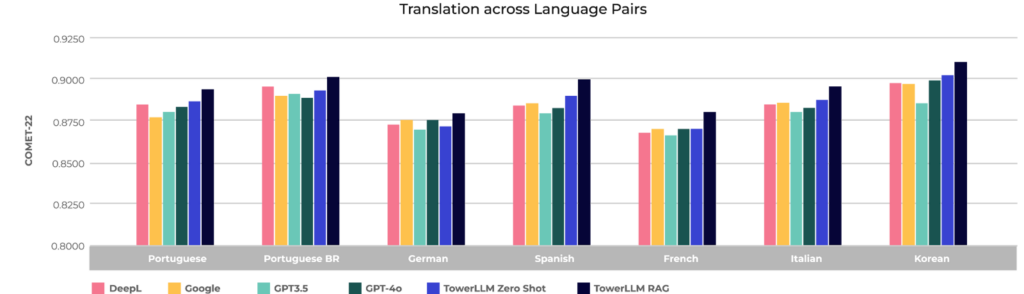
Figure 1: Translation in 14 language pairs
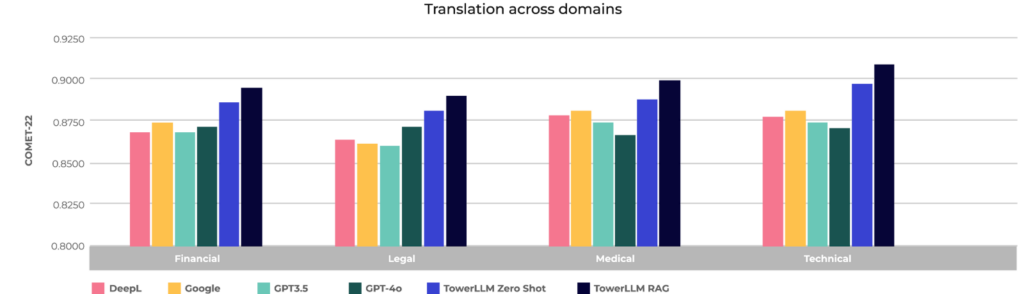
Figure 2: Translation across financial, legal, medical, and technical domains in English-German
The difference in scores is meaningful since COMET tracks the accuracy of translation based on human perception. Unbabel beats other models on average between 0.4 and 1.4 COMET-22 points in the language pair experiment, and between 1.8 and 2.6 COMET-22 points in the experiments on domains, but what does that mean? When TowerLLM scores 0.4 COMET points higher than another model, humans tend to agree that TowerLLM is better than the other model 73.0% of the time. Similarly, when TowerLLM scores 2.6 COMET points higher, humans agree that TowerLLM is better 96.2% of the time. These TowerLLM scores show substantial, clearly perceptible improvements in quality over other models.
Overall, these results show TowerLLM’s strengths in comprehending the nuances of language, capturing the intended meaning, and producing translations that are not only accurate but also natural and fluent. For businesses, these capabilities translate to significant benefits as TowerLLM reduces the need for manual post-editing and review, which simplifies the translation process, resulting in high-quality multilingual communication more frequently and more reliably.
The Future of AI-Powered Translation
TowerLLM represents a significant leap forward in the evolution of AI-powered translation, and as the underlying technology develops and more and more refined data is collected and leveraged, we expect to see performance improve. We also foresee TowerLLM (and other LLMs) solving more and more parts of the translation process, which will make the output more consistent and put human reviewers in a place to make only the most crucial interventions, while steering translation programs from a higher level.
It doesn’t just stop with better machine translation. The combination of TowerLLM’s advanced features and Unbabel’s Quality Estimation technology makes it easier and more reliable for large organizations to move more content to AI translation. With the ability to pinpoint errors and ensure high-quality output, businesses can confidently scale their translation efforts, reduce manual intervention, and achieve faster time-to-market for their multilingual content.
By harnessing the power of advanced language models and combining it with Unbabel’s expertise in machine translation and quality estimation, we’re setting new standards for accuracy, fluency, and cost-effectiveness in multilingual communication.
To learn more about TowerLLM and how it can transform your business’s multilingual communication, visit our landing page and sign up for our webinar. You can also test TowerLLM yourself in our public interface.