Translator Copilot is Unbabel’s new AI assistant built directly into our CAT tool. It leverages large language models (LLMs) and Unbabel’s proprietary Quality Estimation (QE) technology to act as a smart second pair of eyes for every translation. From checking whether customer instructions are followed to flagging potential errors in real time, Translator Copilot strengthens the connection between customers and translators, ensuring translations are not only accurate but fully aligned with expectations.
Why We Built Translator Copilot
Translators at Unbabel receive instructions in two ways:
- General instructions defined at the workflow level (e.g., formality or formatting preferences)
- Project-specific instructions that apply to particular files or content (e.g., “Do not translate brand names”)
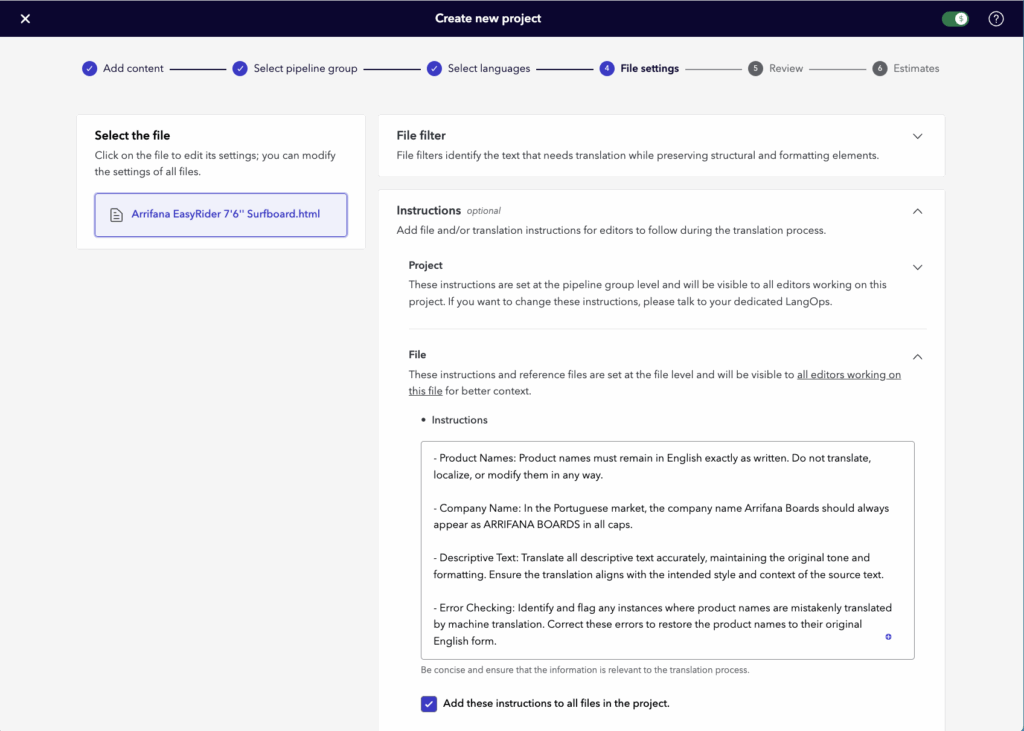
These appear in the CAT tool and are essential for maintaining accuracy and brand consistency. But under tight deadlines or with complex guidance, it’s possible for these instructions to be missed.
That’s where Translator Copilot comes in. It was created to close that gap by providing automatic, real-time support. It checks compliance with instructions and flags any issues as the translator works. In addition to instruction checks, it also highlights grammar issues, omissions, or incorrect terminology, all as part of a seamless workflow.
How Translator Copilot Helps
The feature is designed to deliver value in three core areas:
- Improved compliance: Reduces risk of missed instructions
- Higher translation quality: Flags potential issues early
- Reduced cost and rework: Minimizes the need for manual revisions
Together, these benefits make Translator Copilot an essential tool for quality-conscious translation teams.
From Idea to Integration: How We Built It
We began in a controlled playground environment, testing whether LLMs could reliably assess instruction compliance using varied prompts and models. Once we identified the best-performing setup, we integrated it into Polyglot, our internal translator platform.
But identifying a working setup was just the start. We ran further evaluations to understand how the solution performed within the actual translator experience, collecting feedback and refining the feature before full rollout.
From there, we brought everything together: LLM-based instruction checks and QE-powered error detection were merged into a single, unified experience in our CAT tool.
What Translators See
Translator Copilot analyzes each segment and uses visual cues (small colored dots) to indicate issues. Clicking on a flagged segment reveals two types of feedback:
- AI Suggestions: LLM-powered compliance checks that highlight deviations from customer instructions
- Possible Errors: Flagged by QE models, including grammar issues, mistranslations, or omissions
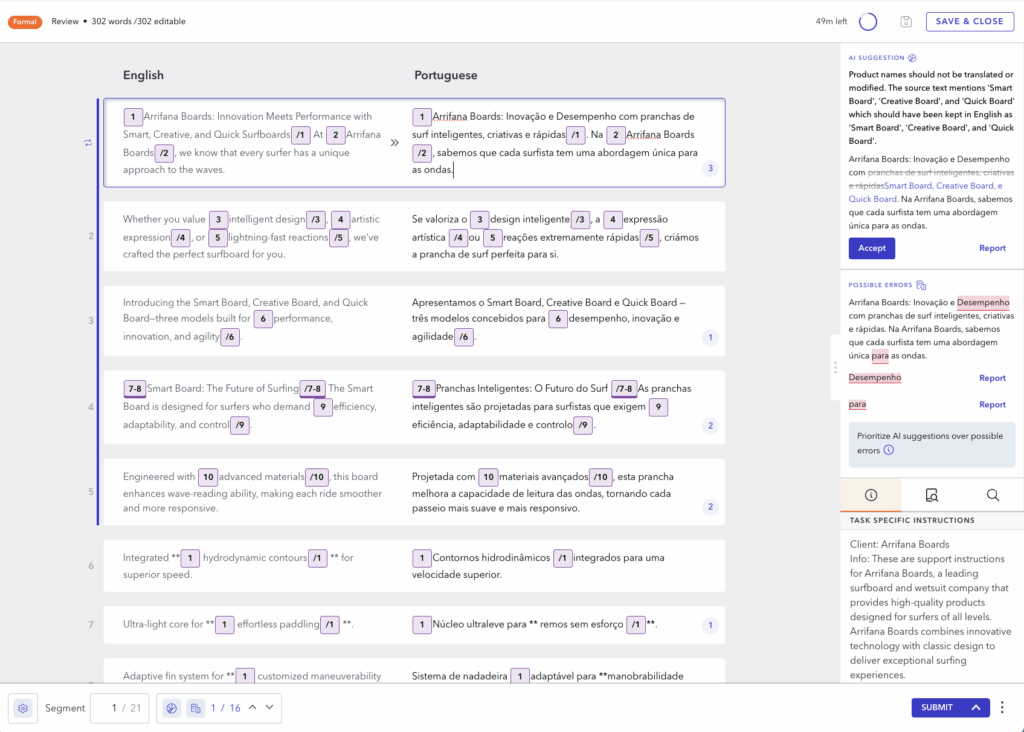
To support translator workflows and ensure smooth adoption, we added several usability features:
- One-click acceptance of suggestions
- Ability to report false positives or incorrect suggestions
- Quick navigation between flagged segments
- End-of-task feedback collection to gather user insights
The Technical Challenges We Solved
Bringing Translator Copilot to life involved solving several tough challenges:
Low initial success rate: In early tests, the LLM correctly identified instruction compliance only 30% of the time. Through extensive prompt engineering and provider experimentation, we raised that to 78% before full rollout.
HTML formatting: Translator instructions are written in HTML for clarity. But this introduced a new issue, HTML degraded LLM performance. We resolved this by stripping HTML before sending instructions to the model, which required careful prompt design to preserve meaning and structure.
Glossary alignment: Another early challenge was that some model suggestions contradicted customer glossaries. To fix this, we refined prompts to incorporate glossary context, reducing conflicts and boosting trust in AI suggestions.
How We Measure Success
To evaluate Translator Copilot’s impact, we implemented several metrics:
- Error delta: Comparing the number of issues flagged at the start vs. the end of each task. A positive error reduction rate indicates that the translators are using Copilot to improve quality.
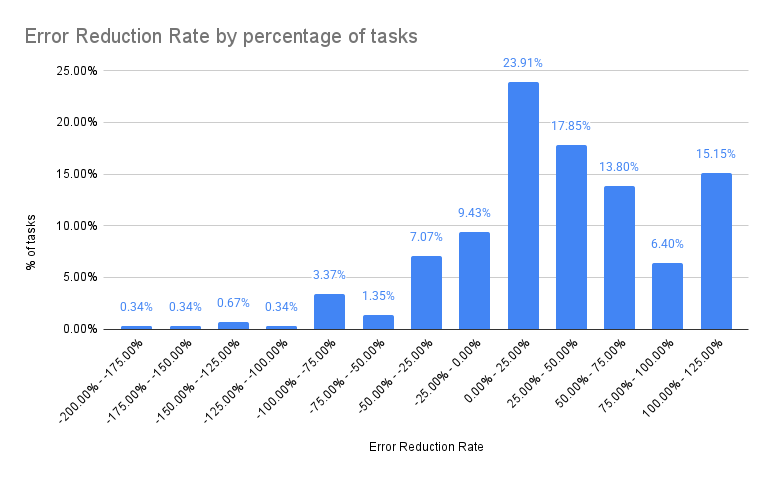
- AI suggestions versus Possible Errors: AI Suggestions led to a 66% error reduction rate, versus 57% for Possible Errors alone.

- User behavior: In 60% of tasks, the number of flagged issues decreased. In 15%, there was no change, likely cases where suggestions were ignored. We also track suggestion reports to improve model behavior.
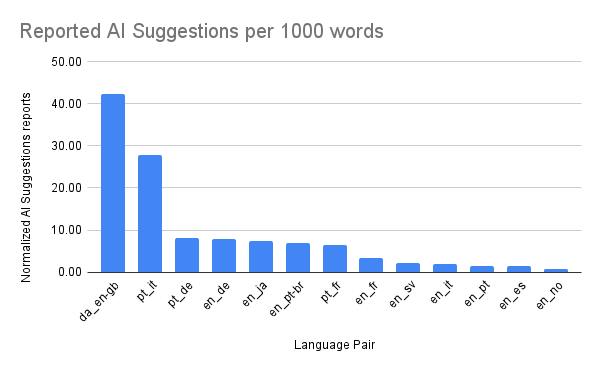
An interesting insight emerged from our data: LLM performance varies by language pair. For example, error reporting is higher in German-English, Portuguese-Italian and Portuguese-German, and lower in english source language pairs such as English-Spanish or English-Norwegian, an area we’re continuing to investigate.
Looking Ahead
Translator Copilot is a big step forward in combining GenAI and linguist workflows. It brings instruction compliance, error detection, and user feedback into one cohesive experience. Most importantly, it helps translators deliver better results, faster.
We’re excited by the early results, and even more excited about what’s next! This is just the beginning.